底层原理初探
问题概览
- 生产者往Broker上发送消息的底层原理
- Broker接受到消息后是如何储存到磁盘的?
- 基于DLedger技术部署的Broker高可用集群是如何进行数据同步的?
- 消费者是基于什么策略选择Master或Slaver拉取数据的?
- 消费者是如何从Broker拉取数据回来进行处理以及ACK的?如果消费者故障了会怎么办?
数据分片机制及消息是如何发送给Broker?
创建Topic的时候为什么需要指定MessageQueue数量?
MessageQueue是RocketMQ中很重要的一个数据分片机制,它将一个Topic的数据拆分成很多个数据分片,然后在每一个Broker机器上存储一些MessageQueue
生成者发送消息时写入哪个MessageQueue?
生成者在发送消息时首先会去请求NameServer,这样就知道了Topic中有多少个MessageQueue,每个MessageQueue分布在哪个broker上了,这样就可以把一个Topic中的数据分散到多个MessageQueue中,然后分散在多个Broker中
如果某个Broker出现故障了怎么办?
如果MasterBroker挂了,此时正在等待的其它Slaver Broker会自动热切换为Master Broker中,但是在自动切换的这个过程中,这一组Broker就没有Master Broker可以写入了,这时通常建议将Producer中开启sendLatencyFaultEnable,当开启后会启动容错机制,如果发现访问某个Broker有延迟500ms,然后还说无法访问,那么就会自动回避访问这个Broker一段时间,比如在接下来的3000ms以内就不会访问该Broker,这样可以避免一个Broker故障后短时间内,短时间内生成者频繁发消息到这个故障的Broker上,出现较多次的异常,等一段时间Master Broker恢复好了,比如Slave Broker已经切换为Master Broker就可以再次访问了
Broker是如何存储数据的?
通过CommitLog消息顺序写入机制,当生产的消息发送到Broker上时,首先将消息写入磁盘上的一个日志文件CommitLog,直接顺序写入文件,如下
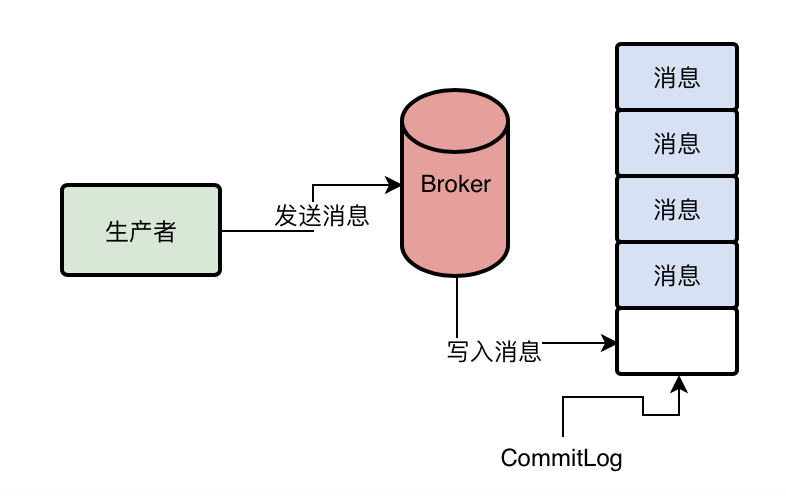
这个CommitLog由多个磁盘文件组成,每个磁盘文件的大小限定为最多1G,Broker接收到消息后就会直接写入到这个文件的末尾,如果一个CommitLog写满1GB后,就会从新创建一个CommitLog文件
MessageQueue在数据储存中体现在哪里?
在Broker中,对Topic下的每个MessageQueue都会有一系列的ConsumerQueue文件,这个ConsumerQueue文件中存储这一条消息对应在CommitLog文件中的offset偏移量、Tag、长度等信息,当Broker接受到一条信息写入CommitLog后,同时会将这条消息在CommitLog中的偏移量offset等信息写入到这条消息所属的MessageQueue对应的ConsumeQueue文件中去
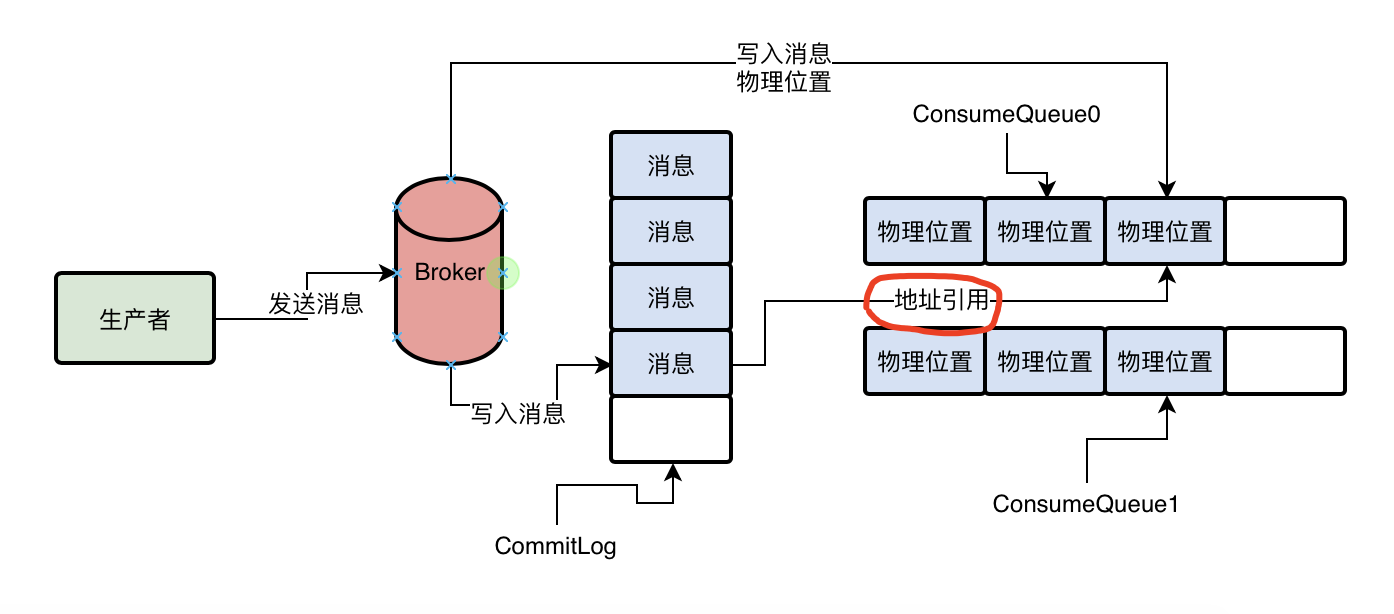
如何做到让消息写入CommitLog文件近乎内存写性能的?
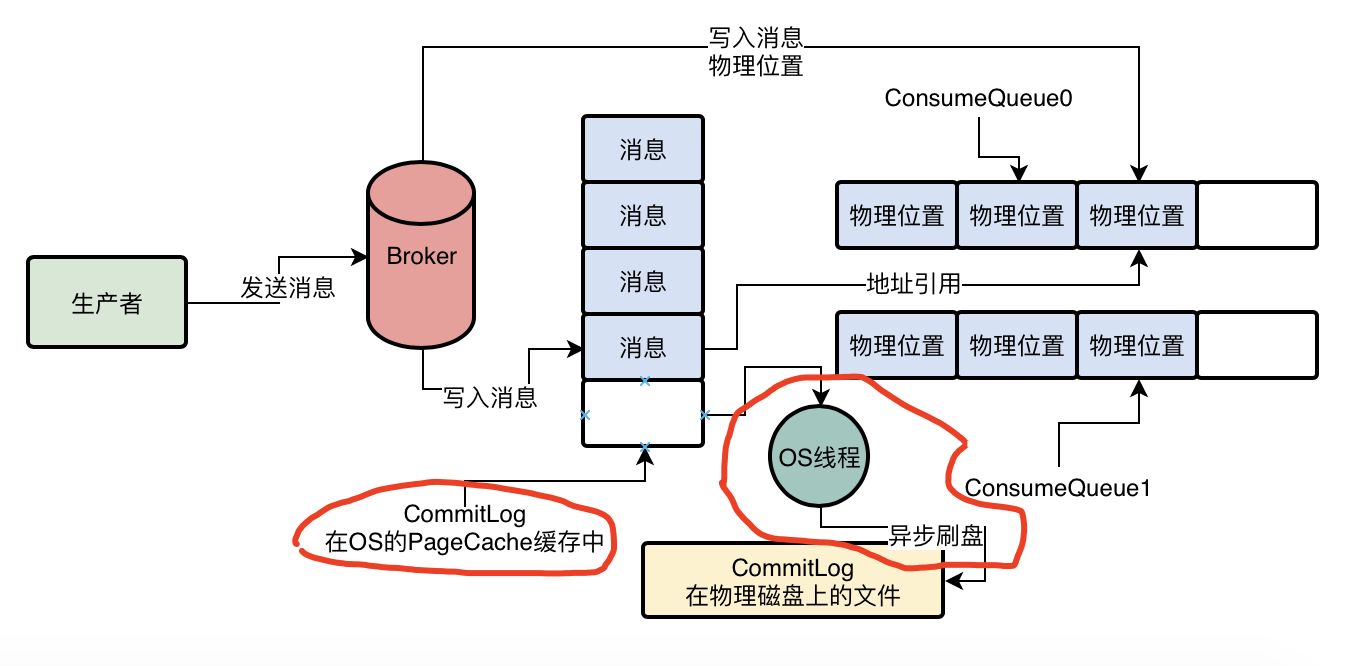
生产者把消息写入到Broker时,Broker会直接把消息写入磁盘上的CommitLog文件,那么Broker是如何提升整个过程的性能的呢?这个部分的性能提升直接影响Broker处理消息的吞吐量,所有Broker采用的是基于Os操作系统的PageCache和顺序写两个机制来提升CommitLog文件的性能的
Broker以顺序写的方式将消息写入CommitLog磁盘文件,也就是每次写入在文件的末尾追加一条数据就可以了,文件进行顺序写的性能要比文件随机写的性能提升很多,数据在写入CommitLog文件的时候,并不是直接写入底层的屋里磁盘文件的,而是先进去OS的PageCache内存中,然后由OS的后台线程选择一个时间,异步化的将OS PageCache缓存中的数据刷入底层的磁盘文件
所以Broker接受到消息后采用磁盘文件顺序写+OS PageCache写入+OS异步刷盘策略,可以让消息写入CommitLog的性能与写入内存中差不多,使Broker具有高吞吐量的消息写入
同步刷盘与异步刷盘
-
异步刷盘:生成者把消息发送给Broker,Broker将消息写入OS PageCache中,就直接返回ACK给生产者了,此时生产者认为消息已经写入成功
存在的问题:当数据在OS PageCache中时,此时Broker发生宕机,那么此时数据就丢失了,但是生产者还以为数据写入成功了
-
同步刷盘:生成者把消息发送给Broker,必须强制将消息刷入底层的物理磁盘中,然后才返回ACK给生产者了,保证的数据不会丢失,如果此时Broker还没来得及将数据刷入磁盘就宕机了,此时对producer来说就会感知到消息发送失败了,只需要不停重试发送,直到Slaver Broker切换为Master Broker就可以接受消息的再次写入了
优点:保证消息不会丢失
缺点:每次强制消息刷入磁盘,必然导致每条数据的写入性能急剧下降,从而导致Broker的吞吐量下降
基于Dledger技术的Broker主从同步原理
Dledger如何实现Broker多副本高可用?
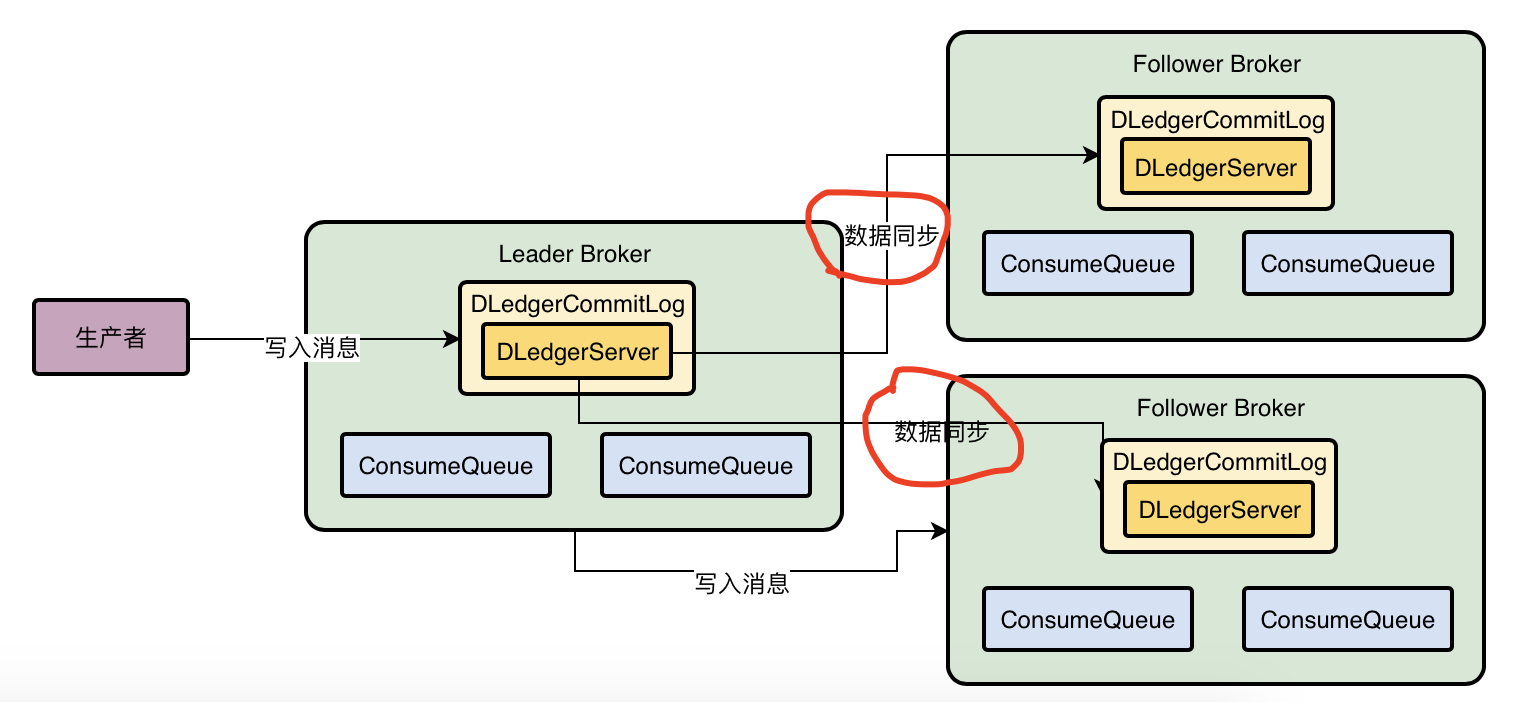
基于Dledger技术替换Broker的CommitLog,Dledger技术有他自己的CommitLog机制,基于Dledger技术实现Broker高可用架构,实际上就是用Dledger先替换掉Broker自己管理的CommitLog,由Dlegger来管理CommitLog,然后Broker还可以基于Dledger管理的CommitLog构建出机器上的各个ConsumeQueue磁盘文件。
一组Broker机器的leader选取,是Dledger基于Raft协议来进行Leader Broker选举的,当三台Broker机器启动时,会先将票投给自己,第一轮选举失败,接着每个Broker会进入一个随机事件的休眠,比如说Broker01休眠3秒,Broker02休眠5秒,Broker03休眠4秒,此时Broker01必然是先苏醒过来的,他苏醒过来之后,直接会继续尝试投票给自己,并且发送自己的选票给别人。接着Broker03休眠4秒后苏醒过来,他发现Broker01已经发送来了一个选票是投给Broker01自己的,此时他自己因为没投票,所以会尊重别人的选择,就直接把票投给Broker01了,同时把自己的投票发送给别人。接着Broker02苏醒了,他收到了Broker01投票给Broker01自己,收到了Broker03也投票给了Broker01,那么他此时自己是没投票的,直接就会尊重别人的选择,直接就投票给Broker01,并且把自己的投票发送给别人。其实只要有(3台机器 / 2) + 1个人投票给某个人,就会选举他当Leader,这个(机器数量 / 2) + 1就是大多数的意思。
这就是Raft协议中选举leader算法的简单描述,简单来说,他确保有人可以成为Leader的核心机制就是一轮选举不出来Leader的话,就让大家随机休眠一下,先苏醒过来的人会投票给自己,其他人苏醒过后发现自己收到选票了,就会直接投票给那个人。
Dledger基于Raft协议进行多副本同步
Dledger在进行数据同步时会分为两个阶段,一个是uncommited阶段,一个是commited阶段
首先Leader Broker上的Dledger收到一条数据之后,会标记为uncommited状态,然后他会通过自己的DledgerServer组件把这个uncommited数据发送给Follower Broker的DledgerServer。接着Follower Broker的DledgerServer收到uncommited消息后,必须返回一个ack给Leader Broker的DledgerServer,如果Leader Broker收到超过半数的Follower Broker返回的ack之后,就会将消息标记为commited状态。然后Leader Broker上的DledgerServer就会发送commited消息给Follower Broker机器上的DledgerServer,让他们把消息标记为commited状态,这就是基于Raft协议实现的两阶段完成的数据同步机制。
